
Introduction
Modern AI applications depend on timely access to relevant data to deliver accurate and meaningful results. While Large Language Models (LLMs) have significantly advanced intelligent systems, their effectiveness is limited by static training data that may be outdated or lack domain-specific context.
Retrieval-Augmented Generation (RAG) enhances language models by retrieving relevant data at runtime, enabling more accurate and context-aware responses while reducing hallucinations. As these systems move into real-world deployment, scalability and performance become critical, making an efficient retrieval layer essential.
ClickHouse provides a strong foundation for building high-performance retrieval systems with vector search capabilities, enabling fast and scalable data access for modern AI applications.
Understanding Retrieval-Augmented Generation
RAG is an architecture that enhances LLMs by integrating a retrieval layer. The process typically involves the following steps:
- A user submits a query
- The system retrieves relevant documents or data
- The retrieved context is passed to the language model
- The model generates a response based on that context
This approach improves accuracy and reduces hallucinations by grounding responses in real data. It also enables systems to provide up-to-date and domain-specific information without retraining the model.
The Need for Scalability
While RAG performs well in controlled environments, production systems introduce new challenges:
- Large-scale data handling
- High concurrency from multiple users
- Strict latency requirements
- Distributed infrastructure demands
A scalable RAG system must be capable of managing millions of records, delivering fast retrieval, and maintaining consistent response times. Without an efficient retrieval layer, the entire pipeline becomes a bottleneck.
Vector Search and Semantic Retrieval
Traditional search methods rely on keyword matching and often fail to capture user intent. They are not optimized for semantic similarity, making them inefficient for embedding-based retrieval.
Vector search provides a more effective approach by representing data as embeddings.
In this process:
- Text is converted into embeddings using machine learning models
- Similarity is computed between query and stored vectors
- Results are retrieved based on semantic relevance
Common similarity measures include cosine similarity and Euclidean distance, which help determine how closely two embeddings are related. This enables systems to understand context and return meaningful results even when exact keywords do not match.
Scalable RAG Pipelines with ClickHouse®
Scalable RAG pipelines with ClickHouse enable efficient vector search and distributed processing for high-performance AI applications. They improve retrieval speed, support large-scale data processing, and ensure low-latency responses in production environments.
Why ClickHouse for Vector Search
ClickHouse is a column-oriented analytical database known for its high performance and scalability. Its support for vector search makes it a strong candidate for building RAG systems at scale.
Key advantages include:
- Fast query execution for large datasets
- Efficient storage and retrieval of vector embeddings
- Scalability through distributed architecture
- Ability to handle real-time analytical workloads
- Integration with existing data pipelines
Unlike traditional vector databases, ClickHouse combines analytical processing with vector search, allowing both large-scale data analysis and semantic retrieval within a single system.
Scalable RAG pipelines with ClickHouse enable efficient vector search and scalable data processing for production-grade AI systems.
Implementation Overview
In ClickHouse, embeddings are stored as vector data and used for similarity search.
Table schema:
CREATE TABLE documents (id UInt64, content String, embedding Array(Float32))
ENGINE = MergeTree() ORDER BY id;Vector search query:
SELECT id, content FROM documents
ORDER BY cosineDistance(embedding, [0.11, 0.40, 0.75]) LIMIT 5;This query returns the most relevant results by comparing vector similarity instead of keyword matching.
Tools and Technology Stack
- Embedding Models: OpenAI or Sentence Transformers
- Orchestration: LangChain
- Database: ClickHouse
- API Layer: FastAPI
System Architecture
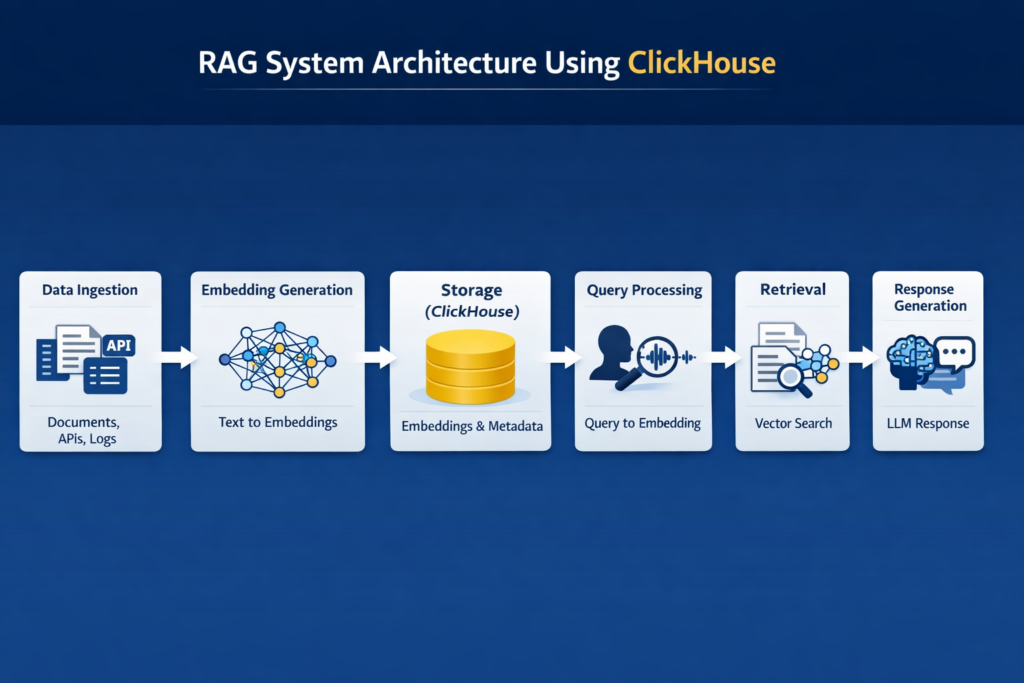
Performance and Design Considerations
Designing a high-performance RAG system requires careful attention to several factors.
Performance optimization:
- Use efficient indexing strategies for vector search
- Limit the number of retrieved results to reduce processing time
- Optimize query execution paths
- Minimize latency to ensure fast user responses
Scalability:
- Deploy ClickHouse in a distributed configuration
- Use horizontal scaling to handle increased load
- Implement load balancing mechanisms
Accuracy:
- Use high-quality embedding models
- Maintain clean and well-structured datasets
- Apply effective prompt engineering techniques
Low latency is especially critical in user-facing systems, as delays in retrieval directly impact the overall response time of the application.
Use Cases
Example: Customer Support Assistant
A user submits a query such as “Why is my payment failing?”. The system converts the query into an embedding and performs a vector search in ClickHouse to retrieve relevant FAQs or logs. The retrieved context is then passed to the language model, which generates a precise and context-aware response.
RAG systems built with ClickHouse can be applied across various domains:
- Enterprise knowledge retrieval systems
- Intelligent customer support assistants
- Healthcare decision support tools
- Recommendation systems
- Log analysis and monitoring platforms
These use cases benefit from improved accuracy and scalability.
Challenges and Mitigation Strategies
Common challenges in RAG systems include:
- Slow retrieval performance
Mitigation: Optimize indexing and query execution - Irrelevant search results
Mitigation: Improve embedding quality and data preprocessing - High latency
Mitigation: Use caching and limit retrieval scope - Scaling limitations
Mitigation: Adopt distributed system architecture
Conclusion
Retrieval-Augmented Generation enables intelligent systems to combine language understanding with real-time data access. Achieving production-level performance depends on designing a scalable and efficient retrieval layer.
ClickHouse supports high-performance vector search, enabling fast and reliable retrieval across large datasets. Integrating RAG with ClickHouse allows the development of LLM applications that deliver accurate and context-aware responses.
As AI systems continue to evolve, the ability to efficiently retrieve and utilize relevant data will play a critical role in ensuring performance, scalability, and reliability.


