
Introduction
As organizations collect terabytes and petabytes of data, a single database server is often no longer sufficient to handle growing storage and query demands. Whether you're processing application logs, IoT telemetry, financial transactions, or user activity, scaling your database becomes a critical challenge.
ClickHouse® is an open-source columnar database management system designed for high-performance analytical workloads. One of its key strengths is horizontal scalability through sharding, which distributes data across multiple servers while maintaining fast query performance.
In this article, we'll explore how sharding works in ClickHouse®, the most common sharding strategies, and best practices for designing an efficient distributed cluster.
What is Sharding?
Sharding is the process of splitting a large dataset into smaller, manageable pieces and distributing them across multiple servers called shards.
Instead of storing all data on a single server, each shard stores only a portion of the dataset. When a query is executed, ClickHouse® automatically sends the query to the relevant shards, processes the data in parallel, and combines the results before returning them to the client.
This distributed architecture enables ClickHouse® to efficiently process billions—or even trillions—of rows while maintaining low query latency.
Why Sharding Matters
As data volume increases, a single server can become limited by CPU, memory, storage, or network bandwidth. Sharding overcomes these limitations by distributing both data storage and query execution across multiple nodes.
Some of the key benefits include:
Horizontal Scalability
Increase storage and compute capacity by simply adding more servers to the cluster instead of upgrading existing hardware.
Faster Query Execution
Queries are processed in parallel across multiple shards, significantly reducing response times for analytical workloads.
Higher Data Ingestion Rates
Incoming data is distributed among shards, enabling higher write throughput for large-scale data ingestion.
Better Resource Utilization
Workloads are balanced across the cluster, preventing a single server from becoming a performance bottleneck.
Understanding ClickHouse® Distributed Architecture
A distributed ClickHouse® deployment typically consists of the following components:
- Shard – Stores a subset of the overall dataset.
- Replica – Maintains a copy of shard data for fault tolerance and high availability.
- Distributed Table – Acts as a logical table that routes queries to all shards.
- ClickHouse Keeper (or ZooKeeper) – Coordinates replication and distributed metadata.
The following diagram illustrates a simplified distributed ClickHouse architecture.
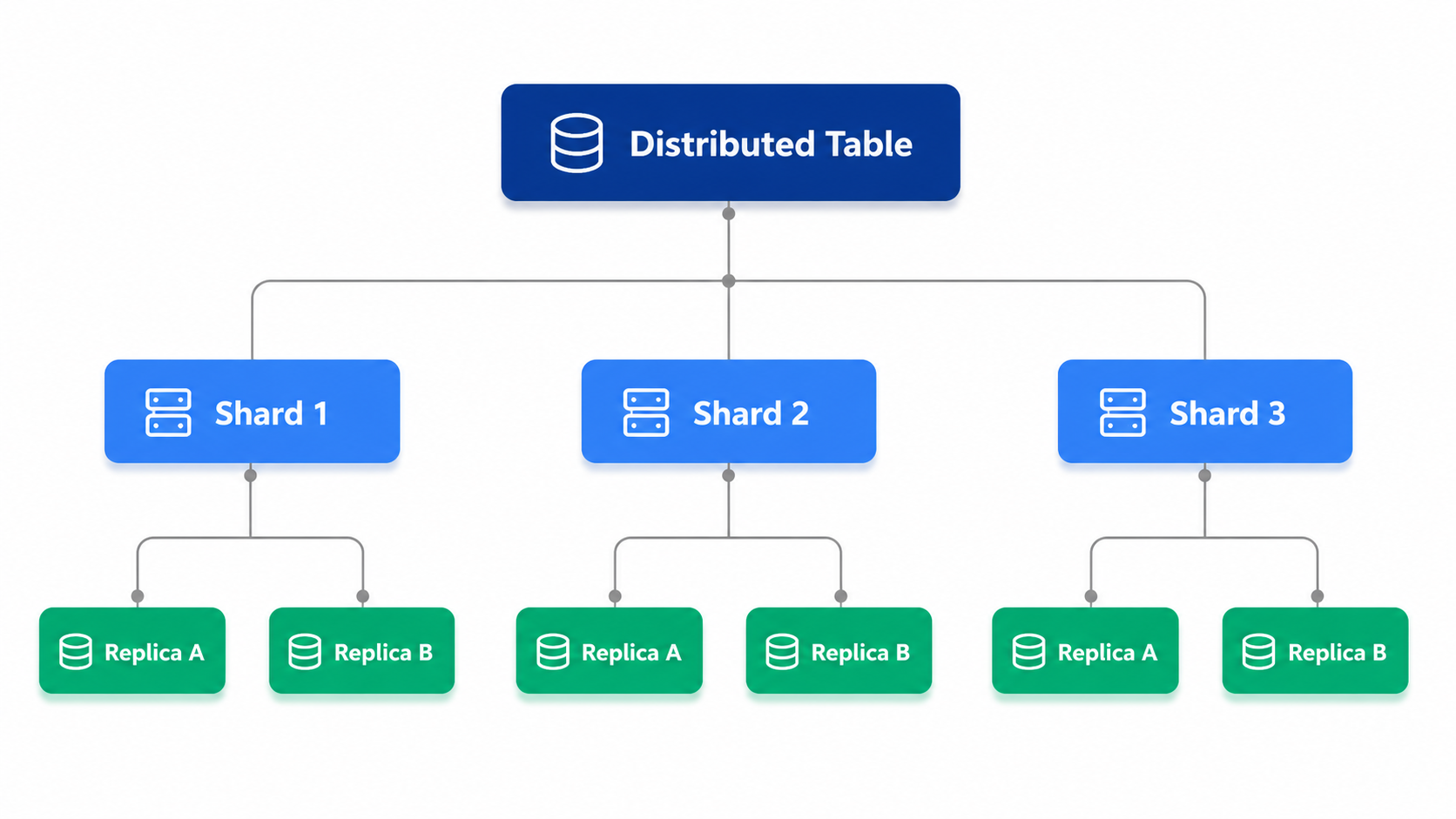
Applications interact with the Distributed table without needing to know where the underlying data resides. ClickHouse automatically routes queries to the appropriate shards, executes them in parallel, and aggregates the results before returning them to the client.
Choosing the Right Sharding Strategy
A sharding strategy determines how data is assigned to each shard. Selecting the right strategy directly impacts query performance, cluster balance, scalability, and operational complexity.
An effective sharding strategy should:
- Distribute data evenly across shards.
- Minimize hotspots and data skew.
- Support common query patterns.
- Reduce cross-shard communication.
- Scale efficiently as data grows.
The following sections explore the most common sharding strategies used in ClickHouse®.
1. Hash-Based Sharding
Hash-based sharding is the most commonly used strategy in ClickHouse®. A hash function is applied to a selected column, such as user_id, and the result determines which shard stores the data.
This approach distributes data evenly across all shards, helping balance storage and query workloads.
Example
cityHash64(user_id) % 4Advantages
- Even data distribution
- Excellent load balancing
- Supports horizontal scaling
- Well suited for large datasets
Limitations
- Range queries may access multiple shards.
- Resharding can be complex when adding or removing shards.
Best Use Cases
- User activity logs
- Event analytics
- Clickstream data
- IoT telemetry
2. Range-Based Sharding
Range-based sharding assigns data to shards based on a range of values. Each shard stores records within a specific range, such as customer IDs or product IDs.
Example
Customer ID 1–1000000 → Shard 1
Customer ID 1000001–2000000 → Shard 2Advantages
- Efficient range queries
- Simple to understand
- Predictable data placement
Limitations
- Uneven data distribution can occur.
- Some shards may become hotspots if new records fall into the same range.
Best Use Cases
- Customer records
- Product catalogs
- Financial accounts
3. Time-Based Sharding
Time-based sharding partitions data according to timestamps, such as day, month, or year. This strategy is widely used for time-series workloads.
Example
2024 Data → Shard 1
2025 Data → Shard 2
2026 Data → Shard 3Advantages
- Fast access to recent data
- Simplifies data retention
- Makes archival easier
Limitations
- Recent shards may receive significantly more traffic.
- Older shards may remain underutilized.
Best Use Cases
- Application logs
- Monitoring data
- Sensor readings
- Time-series analytics
4. Geographic Sharding
Geographic sharding distributes data according to region or location. Each geographic region stores its own data, reducing latency for local users.
Example
Asia-Pacific → Shard 1
Europe → Shard 2
North America → Shard 3Advantages
- Lower query latency
- Improved regional compliance
- Better user experience
Limitations
- Global analytics require querying multiple shards.
- Cross-region operations become more complex.
Best Use Cases
- Global SaaS platforms
- Multi-region applications
- International e-commerce
5. Tenant-Based Sharding
In multi-tenant applications, each tenant or customer is assigned to a specific shard. This provides isolation between customers while allowing independent scaling.
Example
Tenant A → Shard 1
Tenant B → Shard 2
Tenant C → Shard 3Advantages
- Strong tenant isolation
- Easier maintenance
- Flexible scaling for large customers
Limitations
- Large tenants can create uneven shard sizes.
- Balancing tenants across shards requires planning.
Best Use Cases
- SaaS applications
- CRM platforms
- Enterprise software
6. Composite Sharding
Composite sharding combines two or more sharding strategies. For example, data can first be partitioned by region and then distributed using a hash function.
This approach offers greater flexibility for complex deployments while improving scalability and balancing workloads.
Example
Region
├── Hash(User ID)
├── Hash(Customer ID)Advantages
- Better workload distribution
- Improved scalability
- Supports complex business requirements
Limitations
- More difficult to design and maintain
- Requires careful planning and monitoring
Best Use Cases
- Large enterprise deployments
- Global analytics platforms
- High-scale SaaS environments
Comparing Sharding Strategies
Each sharding strategy has its own strengths and trade-offs. The right choice depends on your data model, query patterns, and scalability requirements.
| Strategy | Best For | Advantages | Limitations |
|---|---|---|---|
| Hash-Based | General-purpose workloads | Even data distribution, balanced load | Range queries may access multiple shards |
| Range-Based | Sequential or ordered data | Efficient range queries | Risk of uneven data distribution |
| Time-Based | Time-series data | Easy data retention and archival | Recent shards may become hotspots |
| Geographic | Multi-region deployments | Lower latency and regional compliance | Cross-region queries are more expensive |
| Tenant-Based | Multi-tenant SaaS applications | Tenant isolation and independent scaling | Large tenants can create imbalance |
| Composite | Large enterprise deployments | Flexible and highly scalable | More complex to implement and maintain |
Selecting the Right Sharding Key
Choosing an appropriate sharding key is one of the most important decisions when designing a distributed ClickHouse® cluster. A poor choice can lead to uneven data distribution, overloaded shards, and slower query performance.
When selecting a sharding key, consider the following:
- Choose a column with high cardinality.
- Select a key that distributes data evenly across shards.
- Consider your most common query patterns.
- Avoid keys that generate hotspots.
- Plan for future cluster expansion.
Common sharding keys include:
user_idcustomer_iddevice_idtenant_idcityHash64(user_id)
Handling Data Skew
Data skew occurs when one or more shards store significantly more data than others. This results in uneven storage usage and slower query performance because overloaded shards become bottlenecks.
Common Causes
- Poor sharding key selection
- Low-cardinality sharding columns
- Large tenants or customers
- Uneven regional traffic
- Time-based hotspots
Best Practices to Avoid Data Skew
- Choose a high-cardinality sharding key.
- Use hash-based sharding whenever possible.
- Monitor shard sizes regularly.
- Rebalance data when adding new shards.
- Review query patterns before changing the sharding strategy.
Replication vs. Sharding
Sharding and replication solve different problems but are often used together in production ClickHouse® deployments.
- Sharding distributes data across multiple servers to improve scalability and query performance.
- Replication maintains copies of data to provide high availability and fault tolerance.
| Sharding | Replication |
|---|---|
| Splits data across multiple servers | Copies data across multiple servers |
| Improves scalability | Improves availability |
| Increases storage capacity | Protects against server failures |
| Enables parallel query execution | Provides fault tolerance |
| Balances workload across shards | Keeps data synchronized between replicas |
Most production ClickHouse® clusters combine both approaches to achieve high performance and reliability.
Example Cluster Design
A typical production deployment might consist of:
- 2 Shards
- 2 Replicas per Shard
- 1 Distributed Table
- ClickHouse Keeper Cluster
This architecture provides:
- Horizontal scalability
- High availability
- Fault tolerance
- Parallel query execution
Such a configuration is commonly used for production analytics workloads where both performance and reliability are essential.
Best Practices
Follow these best practices to build and maintain a scalable ClickHouse® cluster:
- Choose a sharding key with high cardinality to distribute data evenly.
- Use hash-based sharding for general-purpose analytical workloads.
- Monitor shard sizes regularly to identify and resolve data skew.
- Combine sharding with replication for scalability and high availability.
- Keep shard configurations consistent across the cluster.
- Monitor query performance using the system tables.
- Plan for future growth by designing a sharding strategy that can scale as data volume increases.
- Test your sharding strategy with realistic workloads before deploying it to production.
Key Takeaways
- Sharding enables ClickHouse® to scale horizontally across multiple servers.
- Hash-based sharding is the preferred choice for most analytical workloads.
- Selecting the right sharding key helps avoid uneven data distribution.
- Combining sharding with replication provides both scalability and high availability.
- Regular monitoring helps maintain balanced workloads and optimal query performance.
Conclusion
Sharding is a fundamental technique for scaling ClickHouse® to handle large analytical workloads. Selecting the right sharding strategy helps distribute data efficiently, improve query performance, and maximize resource utilization.
Whether you choose hash-based, range-based, time-based, geographic, tenant-based, or composite sharding, the best approach depends on your data model, workload, and business requirements.
By combining a well-designed sharding strategy with replication, continuous monitoring, and regular performance tuning, you can build a ClickHouse® cluster that is scalable, resilient, and capable of delivering fast analytics as your data grows.


